Message-Passing Programs
Last updated on 2025-09-17 | Edit this page
Estimated time: 30 minutes
Overview
Questions
- What is the distributed-memory programming model?
Objectives
- Learn about message-passing in distributed-memory computing.
- Understand the strengths and limitations of this approach.
The Message-Passing Paradigm
While multi-threaded parallelization is very efficient when running on a single compute node, at times we need to apply even more compute power to a single job. Since this will involve more than one compute node, we will need a separate but identical program running on each computer which leads us to a new programming paradigm. This is known by various descriptive names including MPMD or Multiple Program Multiple Data, but is more commonly known as message-passing which is how data is exchanged between multiple identical copies of a program that each operate on different data. There is a common syntax used which is MPI or the Message-Passing Initiative standard. C/C++ and Fortran have several MPI implementations including free OpenMPI and MPICH libraries and commercial Intel MPI, while Python uses mpi4py which implements a stripped down version of the MPI standard. R does not have any message-passing implementation though there was work on Rmpi in the past that was never completed.
The diagram below shows what a distributed-memory dot product looks like on a multi-node computer in contrast to the shared-memory program in the diagram in the previous chapter. In this case, our job is running on 4 cores on node 1 and 4 cores on node 2. Distributed-memory means that there will be 8 identical programs running, with 4 on each node, but each will have responsibility for doing one eighth of the calculations. We will need to use the mpirun or mpiexec commands to launch eight copies of the program on the two nodes then start them running. The jobs will handshake then decide which part of the data each is responsible for. After all nodes have calculated their partial sums, they will be globally summed across all 8 tasks using the network if needed then the program with lowest rank will print out the results.
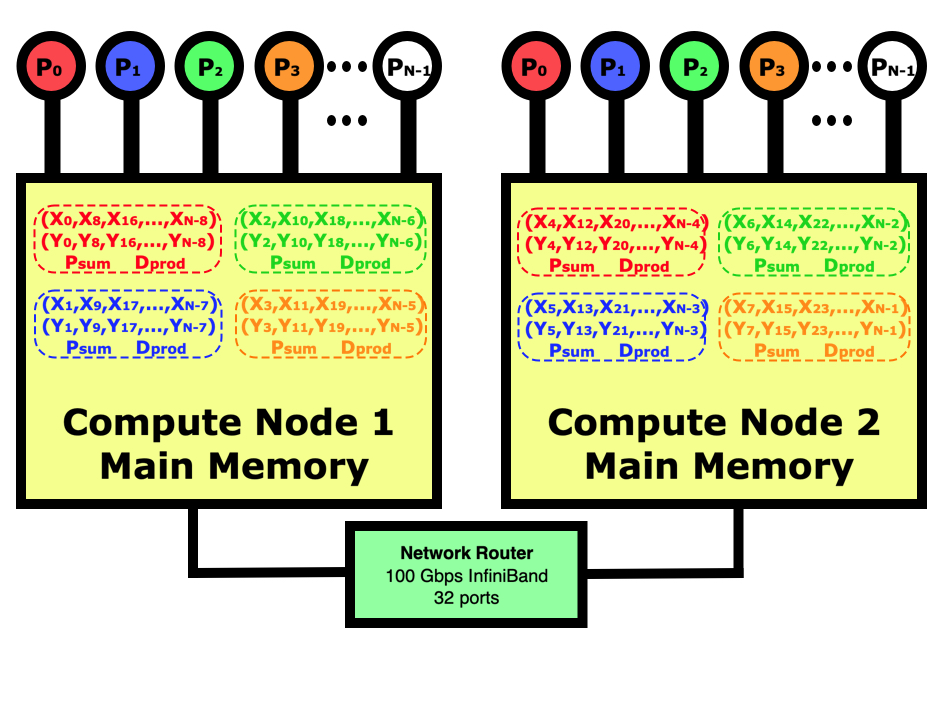
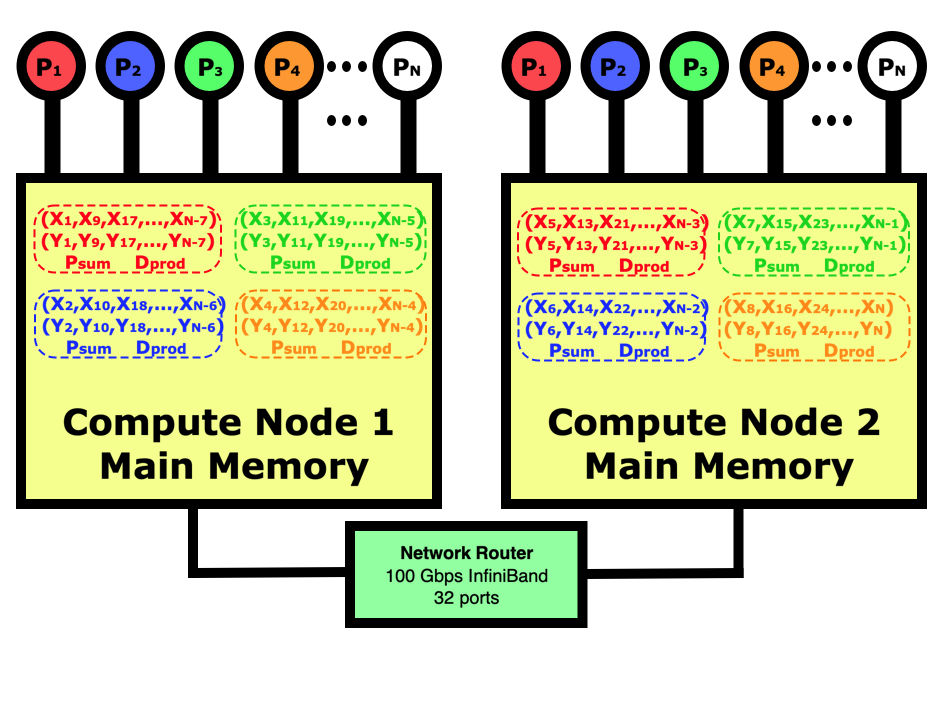
In parallel computing, the programmer must decide how to divide the data between the processes. In this case, we could have just as easily decided that rank 0 is responsible for the first 1/8th of the elements, rank 1 for the next 1/8th, etc. If we were reading in the data and distributing it in blocks to each other process then this would be better since we wouldn’t have to move the data around before sending out each block of data. In this case for the dot product, it simply doesn’t matter. Regardless of how the work is divided, it sometimes does not come out evenly so you do have to make sure that all work is accounted for even if some processes have to do slightly more.
The message-passing dot product code
Let’s look at how the message-passing version of the code differs from the original scalar version and contrast it to the multi-threaded version. If you are using Python, you first need to pip install mpi4py into your virtual environment then you can import mpi4py as MPI to bring the package into your code. The compiled languages C/C++/Fortran need an #include<mpi.h> to pull in the headers for MPI, then you compile with mpicc or mpifort.
Since a message-passing job is many identical copies of the same program working on different data, we need to use the mpirun -np 4 command for example to launch 4 copies of the code. If you are running the job using a scheduler like Slur, this will run on the 4 cores that you requested. If you are not running through using a scheduler, you can specify different compute node names such as mpirun –host node1,node1,node2,node2 to run on 2 cores of node1 and 2 cores of node2. You can also specify a hostfile and number of slots using mpirun –hostfile hostfilename where the host file contains lines having the node name and number of slots on that node (node1 slots=2).
All message-passing programs start with an initialization routine which for Python is the comm = MPI.COMM_WORLD statement and C/C++/Fortran is MPI_COMM_WORLD. This says that our communicator includes all ranks available (COMM_WORLD), and it connects with all the other programs. The other two lines that are at the start of every message-passing program are functions to get the number of ranks, the message-passing word for threads, and the rank for each program which ranges from 0 to the number of ranks minus 1. This rank is what the programmer uses to decide which data each copy of the program will work on, and is also used to identify which copy of the program to pass messages to.
Each rank is responsible for doing the dot product on part of the data, and the programmer must decide on how to divide this work up. For this code, we are going to divide the work up in a similar way to how the multi-threaded program worked, where the rank 0 is responsible for indices 0, nranks, 2nranks, 3nranks, etc. The initialization of the X and Y vectors shows how we are now just dealing with N_elements each (N/nranks) but we still want the initialization to be the same so we have to change that a bit.
We do a barrier command before starting the timer so that all the ranks are synchronized. Normally it is good practice to avoid barriers in codes, but in our case we are doing it so we get a more accurate timing.
Each rank calculates a partial sum of the indices that it is responsible for. Then all ranks must participate in a reduction to globally sum the partial sums. Notice at the end that we only have the lowest print its results. If we didn’t protect the print statements like this, we would get nranks copies of each print statement.
If you want to try other examples of MPI code, the scalar algorithm for a matrix multiply is very simple but you can compare that to the MPI versions in the links below. These algorithms are much more complicated since you need to have particular columns and rows in the same rank in order to perform the vector operations. This involves a great deal of communication and the programmer must determine the optimal way to handle the message passing to minimize the communication costs and memory usage.
We see from all this that parallelizing a program using message-passing requires much more work. This is especially true in more complex programs where often you need to read input in on the lowest rank and broadcast the data out to the other ranks. Most of the time there is also a lot of communication needed during a calculation that requires sending data from one rank to the other. In these cases, there must be a pair of send and receive statements to specify the starting data, what node to send it to, and on the receiving rank you must specify the source rank and where to put the data. The nice thing about message-passing is that the libraries do all the work of interacting with the underlying communication system for you.
So while message-passing is more difficult to program, the supporting libraries are very sophisticated in simplifying the process. With multi-threading, your algorithm is limited to the number of cores on a single compute node, but the message-passing model has no limits. People have run message-passing codes on millions of cores on supercomputers worth as much as half a billion dollars.
Understanding what can cause inefficient scaling
In many practical message-passing codes, we would need to read data into one of the ranks, divide the data up and send it out to each other node. This extra communication is necessary but does lead to some inefficiency to be aware of. Real message-passing applications also usually require communication mixed in with the computational part in order to move data to where it needs to be for the calculations. Advanced programmers can try to minimize this by hiding the communications behind the calculations using asynchronous communication calls. All this communication can slow down the job, and this usually gets worse as you spread a job over more cores, and especially over more compute nodes. It is therefore usually best to keep the processes in a run on as few compute nodes as possible so that most of the communication is being done within a node by memory copies that are faster than sending data between nodes across network cards.
Networks in cluster supercomputers like those typical in universities are usually not uniform. Performance within a switch which may connect 32-40 compute nodes may be very fast, but if your job is spread on different network switches it can be much slower since switches may be connected to each other at much lower aggregate bandwidths. In Slurm you can request that your job be run on just one switch by using –switches=1 but this is not always honored.
All of this does sound more complicated as message-passing programming is definitely more complex than the multi-threaded approach. But if you really need to apply more computing power to your job, it is the only way to go.
Scaling Study of the Distributed-Memory Dot Product Code
- Distributed-memory computing is very flexible, extremely scalable, but more difficult to program.
- Understand key factors that can limit the efficient scaling of message-passing programs.