Performance Concepts
Last updated on 2025-10-07 | Edit this page
Estimated time: 40 minutes
Overview
Questions
- What does performance mean in programming?
- How do I take advantage of optimized libraries?
Objectives
- Understand that what actually goes on in the computer may be much more complex than what the user tells the computer to do.
- Have a basic understanding of some of the performance issues to be aware of.
- Learn that you don’t have to be an expert programmer to take advantage of advanced performance techniques, you just need to be aware of how to use libraries optimized by experts.
Conceptual View
When we write a program for a computer, we view the operation from a more conceptual level. The picture below is for a simple dot product between two vectors X and Y, where the dot product Dprod is the sum of the elements of each vector multiplied together. Notice first that the indexing for arrays in Python starts at 0 and goes to N-1. This varies between languages, with C/C++ also starting at 0, while R, Matlab, and Fortran start arrays at 1 and go to N.
When we think of a computer running a program to do this calculation, we view it as starting with the variable Dprod being pulled from main memory into the processor where this sum is zeroed out. We then pull the first element of X and the first element of Y into the registers and multiply them together then summing them into Dprod. We loop through all elements of the vectors, each time pulling the X and Y element into memory, multiplying them together and summing them into Dprod. Then at the end, we push Dprod back down into main memory where the program prints the result out to the screen.
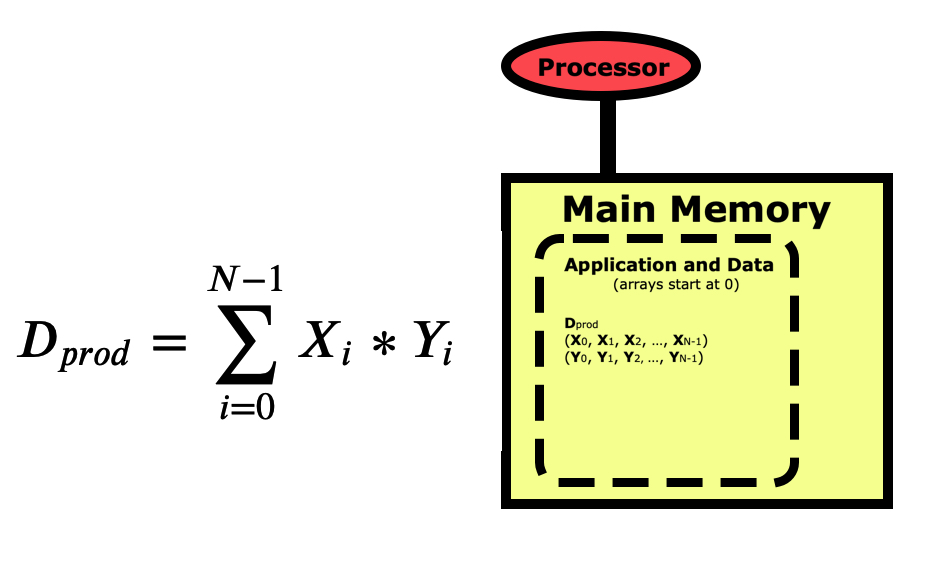
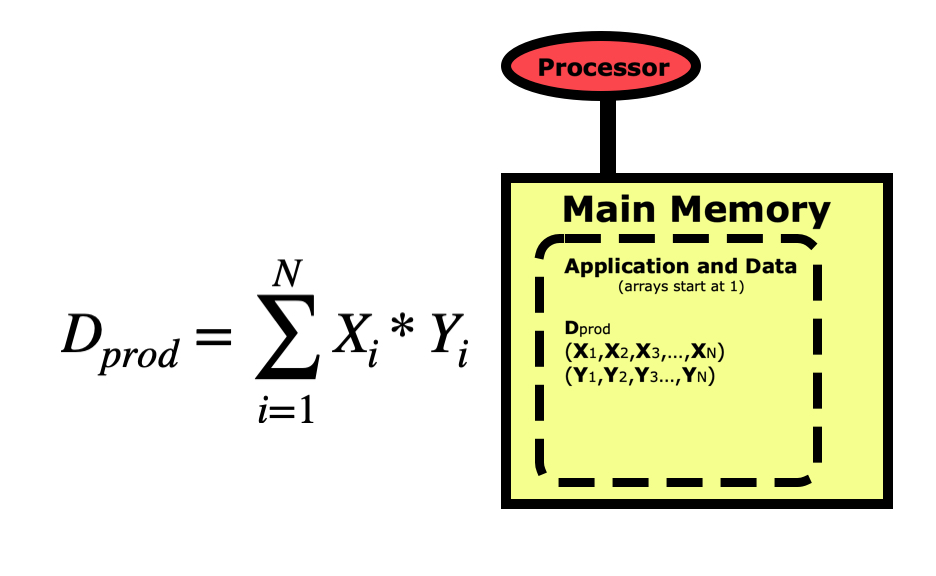
This conceptual view of what the computer is doing is all we really need to be aware of when we are starting to writing programs. But when those programs start taking too long to run on a personal computer then we need to understand what the computer is doing in more depth so we can make sure that the code is running optimally. Computers are internally quite complex, so fully understanding how code can be written in different ways to streamline the processing can be very challenging. Fortunately, not everyone needs to be able to write optimal low-level code. For most of us, we just need to understand what programming techniques in each language may cause performance problems, and understand how to take advantage of optimization libraries that experts have written for us.
The Computer’s View
Let’s walk through the same dot product example again, but this time looking at it from the point of view of the computer rather than our conceptual view. The first thing to understand is that when you pull a variable up from main memory into the registers in a processor, what goes on behind the scene is very complicated, but fortunately for us also totally automated. Variables don’t get pulled up individually but as part of a 64-byte cache line. The variables in this cache line get promoted through several layers of increasingly fast memory known as cache layers, with a copy of the entire cache line being left behind in each layer. In this way, the most frequently used data will be more likely to be in one of the cache layers where it can be accessed more quickly. In the case of our dot product, that means loading the first element of X and its 64-byte cache line may take 10-33 ns while the next 7 only take 0.3-1 ns since those elements are now in L1 cache too.
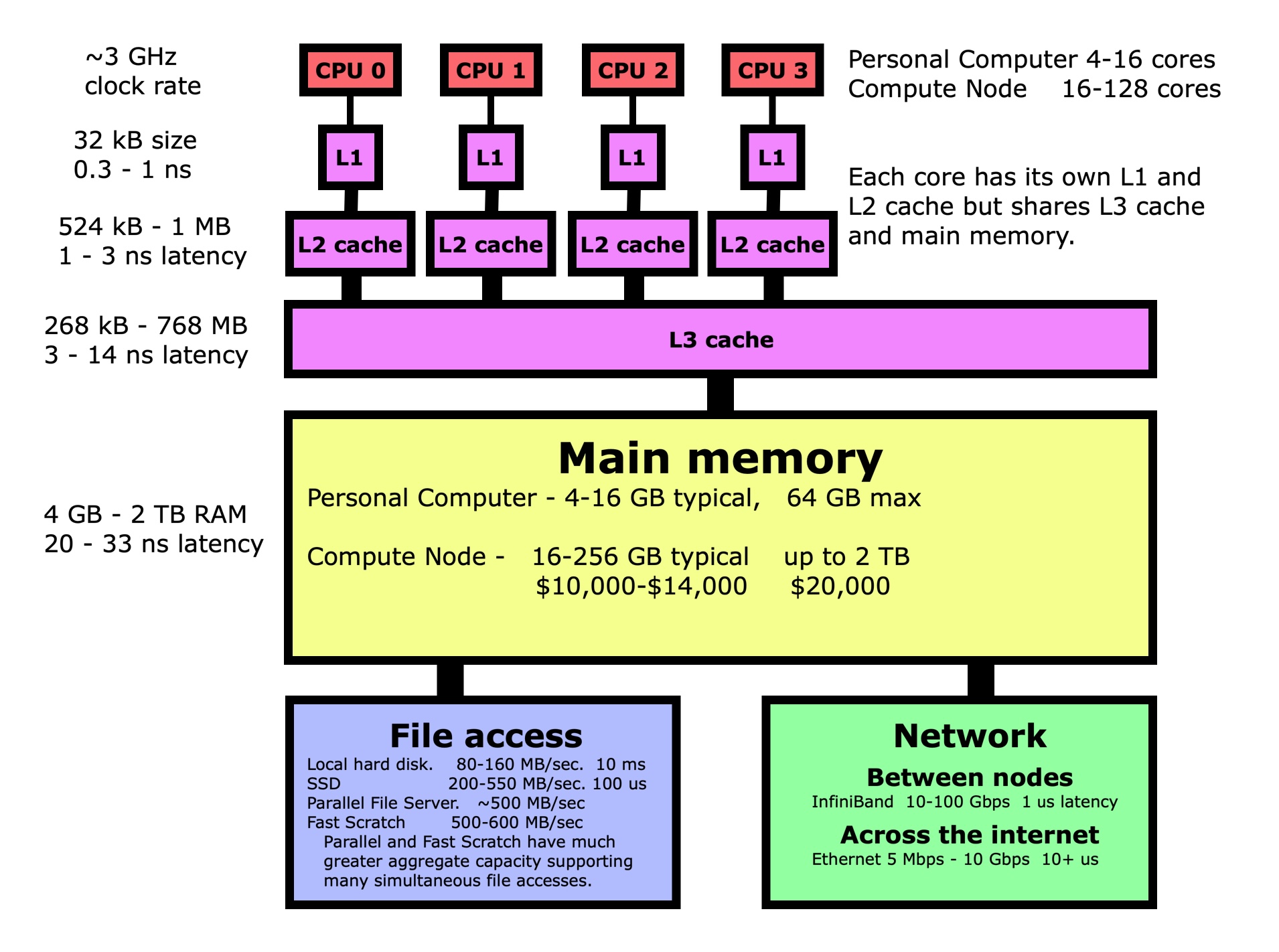
How does this knowledge help us? Performance is more about getting data to the processor since most operations are very fast once the data is in the processor registers. If the vector is instead not stored in contiguous memory, with each variable in the next memory location, then the subsequent 7 memory loads of X and Y will take 20-33 ns each instead of 0.3-1 ns each. This means that we need to ensure that variables we are using are in contiguous memory whenever possible. There will be an exercise at the end of this section where you will measure the difference in execution time between these two cases.
Now let’s look at a simple matrix multiplication algorithm which is fairly simple to program, but may have very different performance depending on how you write the code.
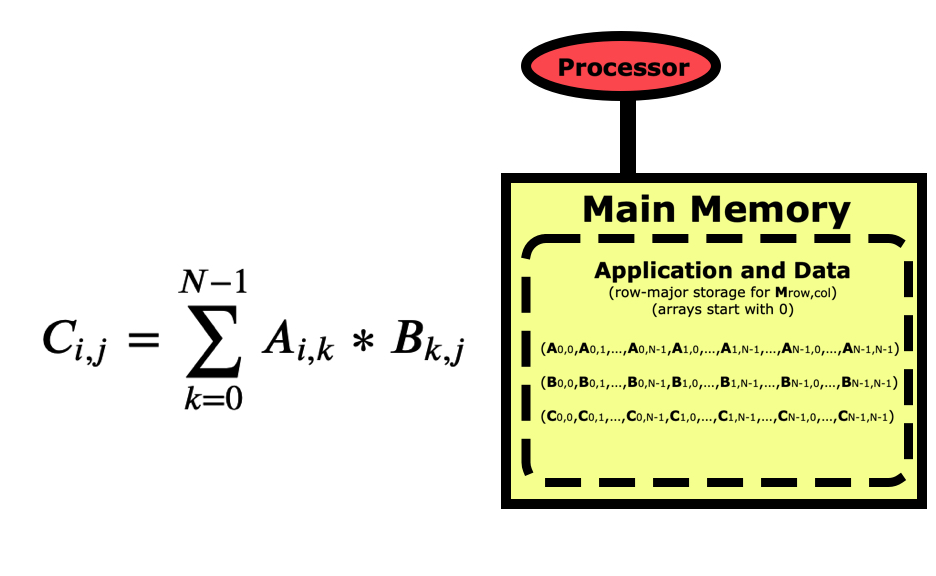
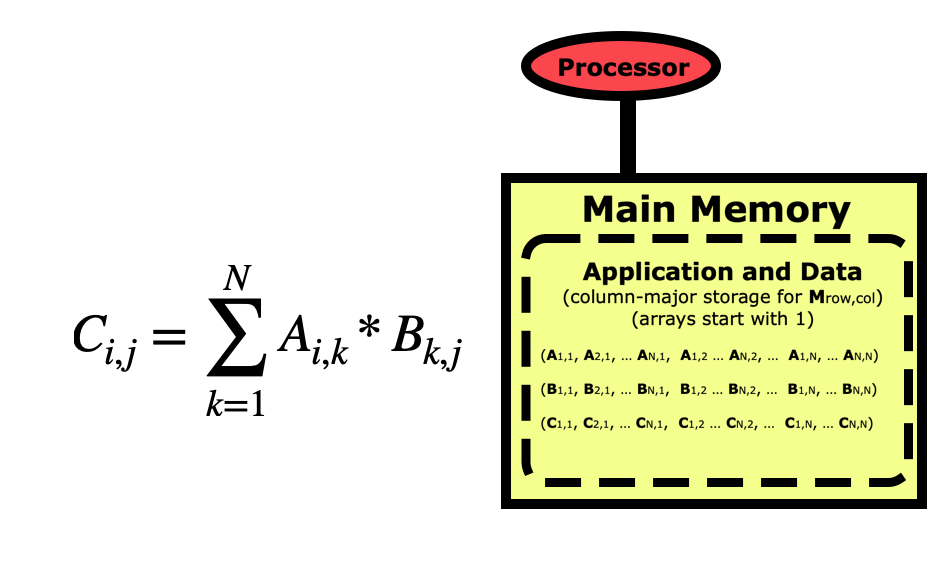
Once the matrices are initialized, the code to multiply them together is fairly simple.
But if we are concerned about performance, we need to take a better look at this code. Python is a row-major language like C/C++, which means matrices like this are stored by rows first as in the picture above. If we look at this code from a cache-line point of view, then it looks optimal for the B matrix since when we load an element the others in the cache line will get used in the next loop iterations, but the A matrix is the opposite where elements being used next are farther apart.
But it turns out this isn’t really the way to look at performance in this case. For each element of C that we calculate, we will need N elements of A and N elements of B. So every element of A and every element of B will get re-used N times during this calculation. What is important is that when we pull each element into the L1 cache where it is the fastest to access, we want to re-use it as much as possible rather than having to pull it repeatedly from the lower caches or main memory.
An optimal approach has been developed in the past that pulls blocks of each matrix into L1 cache. This block optimization results in a much more complicated code, but also a much higher performing one. The good news is that for users like us, we don’t have to ever program it ourselves, we just need to know that it is in optimized libraries that we can call at any time. Below are some examples of how to access the low-level optimized libraries in the various languages.
So while writing a matrix multiplication code from scratch is not difficult, using the optimized function accessible from each language is easier and guarantees the best performance. To find out how much difference there is in performance, you will need to try for yourself by measuring the execution time for a few different matrix sizes in the exercise below.
Measuring Cache Line Effects
Time Different Matrix Multiplication Methods
Advanced Exercise - Transpose B to cache-line optimize it
As k is incremented in the innermost loop, elements of A are being brought into cache efficiently since they are stored in contiguous memory, as we learned from the dot product example. Unfortunately, elements of B are not since they will be sparse, separated by N-1 elements each time. While in most languages we already know that we can simply use the optimized library routine speedup the code, if this wasn’t available one thing we’d consider is to transpose the B matrix so that it is stored in column-major format before doing the matrix multiplication. If you’re up for a challenge, try programming this up to see if it improves the performance compared to the original code.
There are a great many levels of optimization that can be done to the matrix multiplication algorithm. Transposing B should improve the performance some. For a more complete overview of what is done in the np.matmult() algorithm and others like it, follow the link: https://en.algorithmica.org/hpc/algorithms/matmul/
Summary
When it starts taking longer to run a given program, we need to start looking beyond just whether it gives the correct answer and begin considering performance. This means we need to go beyond the conceptual view of how the program runs to look at how it makes use of the underlying hardware architecture. While this can get very complicated very quickly, most users just need to be aware of where performance bottlenecks can occur in order to avoid them. Quite often, writing optimal code just means taking advantage of highly optimized libraries that experts have written and tuned. So most of us just need to know when and where to look for these optimized routines in order to write highly optimized code.
- A computer’s view of code is more complex than a user’s view.
- It’s important to understand a little about what goes on when code actually runs, but you don’t need to be able to program at that level.
- Whenever possible, use code written and optimized by experts instead of writing your own version.